
看護師国家試験をデータベース化しようとしているうちに、自分の全体的な医学知識をアップデートした方がいいのではないかと考えるようになりました。
医師になって 45 年、消化器系のカンファレンスはそれなりに経験してきましたが、全体的な医学知識においては全く進歩していない部分も多く、現在の若手医師のように詳細な知識は無理としても、できる限り知識を集めて感覚を磨いておいた方がいいと思います。
その材料として何がいいかと考えたのですが、まずは医師国家試験問題を使ってそれをデータベース化しようと思いました。
python による pdf からのテキスト抽出
厚労省のこのページに 2023 年の医師国家試験問題の pdf ファイルがあってダウンロードができるようになっています。この中のA問題を使用します。
次のような python プログラムを作成します。
import fitz
class Examtxt():
def __init__( self ):
self.pdf = '~/A1.pdf'
self.tgttxt = '~/target.txt'
self.totaltxt = ''
def extract_text( self ):
doc = fitz.open( self.pdf )
text = ""
for page in doc:
text += page.get_text()
self.totaltxt = text
def writeTxt(self):
with open( self.tgttxt, mode='w') as f:
f.write( self.totaltxt )
if __name__ == '__main__':
extxt = Examtxt()
extxt.extract_text()
extxt.writeTxt()
A 問題の最初の 6 ページを削除して上のプログラムを実行すると、以下のように target.txt が瞬時に作成されます。
DKIX-01-AH-7
1
1 母体背景と胎児疾患の組合せで正しいのはどれか。 3 つ選べ。
a 高齢妊娠 13trisomy
b 風疹感染 先天性心疾患
c 妊娠高血圧症候群 不整脈
d 全身性エリテマトーデス 頭蓋内出血
e パルボウイルス B19 感染 貧 血
2 アレルギー性鼻炎の診断で原因抗原を特定するために行う検査はどれか。 2 つ選
べ。
a プリックテスト
b 鼻汁好酸球検査
c 血清総 IgE 検査
d 末梢血好酸球数測定
e 血清特異的 IgE 検査
3 胃全摘術後にみられる可能性があるのはどれか。 3 つ選べ。
a 胆 石
b 肥 満
c 貧 血
d 耐糖能異常
e 門脈圧亢進
DKIX-01-AH-8
2
4 急性好酸球性肺炎について誤っているのはどれか。
a 胸水貯留
b IL-5 上昇
c 末梢血好酸球数正常
d 片側性すりガラス陰影
e 気管支肺胞洗浄液中の好酸球数増加
5 女性に多いのはどれか。
a 双極Ⅰ型障害
b アルコール依存症
c 自閉スペクトラム症
d 神経性食思〈欲〉不振症
e 反社会性パーソナリティ障害
6 溶血性尿毒症症候群でみられるのはどれか。 2 つ選べ。
a LD 高値
b 破砕赤血球
c 血清補体価低値
d 網赤血球数低値
e 抗 ADAMTS-13 抗体陽性
これは最初の 2 ページですが、看護師国家試験問題とは異なり文字化けがありません。
看護師国家試験問題の文字化けは著作権とか厚労省の嫌がらせではなくて、たまたま偶然にあのようになったようです。
正規表現を使って問題文を抽出する
正規表現は苦手ですが、とても便利なものです。
DKIX-01-AH-n page を削除
まずは、文書の ID でしょうか、「DKIX-01-AH-7」とページ数の数字を削除します。
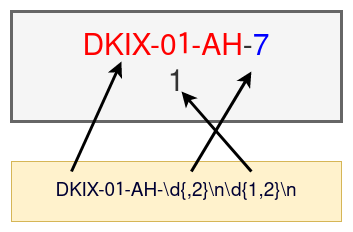
「DKIX-01-AH-」までは共通していますが、7はどんどん変化します。ページ数も変化します。
なので上の正規表現の意味は、「DKIX-01-AH-で始まって、2桁までの数字が続き、改行コードがあって、さらに2桁までの数字があって最後に改行コードを伴うもの」です。これを削除するためには、
self.totaltxt = re.sub(r'DKIX-01-AH-\d{,2}\n\d{1,2}\n', '', self.totaltxt)
これで削除できます。
選択肢を削除する
選択肢は、
a 高齢妊娠 13trisomy
のように「全角のアルファベットで始まり、改行コードで終わり」ます。なので、
self.totaltxt = re.sub( r'[a-z].+\n', '', self.totaltxt )
で削除できます。
別 冊 No. 3 A、Bの削除
設問文中に別冊情報があるので、その後出てくる別冊情報を削除します。
self.totaltxt = re.sub( r'別 冊\n.+\n', '', self.totaltxt )
設問番号を装飾する
目的は問題文のデータベース化なので、問題番号と問題文を正確に抽出する必要があります。
そのために設問番号に装飾を加えます。
self.totaltxt = re.sub(r'(\d+) (.*)', r'問題\1-----\2', self.totaltxt)
この正規表現はとても難解です。

あるテキストに ‘(\d+) (.*)’ (間は全角スペース)で正規表現を適応すると、カッコでグループ化された順番にキャプチャされます。そしてそれは「\1」「 \2」 などで呼び出すことができます。
この場合は、(\d+) が最初のグループで全体の正規表現に当てはまる文字列の中から、数字が1番目に変数として格納されます。その後の文字列は 2 番めの変数です。
この正規表現を実行すると、以下のようになります。
問題1—-母体背景と胎児疾患の組合せで正しいのはどれか。 3 つ選べ。
問題2—-アレルギー性鼻炎の診断で原因抗原を特定するために行う検査はどれか。 2 つ選
べ。
問題3—-胃全摘術後にみられる可能性があるのはどれか。 3 つ選べ。
問題4—-急性好酸球性肺炎について誤っているのはどれか。
問題5—-女性に多いのはどれか。
日本語間の半角スペースを削除する
日本語間に半角スペースが入っている部分があるのでそれを削除します。
この正規表現は Qiita のこのページから頂いたものですが、実はなぜこれでうまくいくのかが理解できません。最初の半角スペースが削除される理由はわかるのですが、すべての日本語間の半角スペースが削除される理由がどうしてもわかりません。でもうまくいくならそのまま使わせて頂きます。
self.totaltxt = re.sub('([あ-んア-ン一-龥ー])\s+((?=[あ-んア-ン一-龥ー]))', r'\1\2', self.totaltxt)
改行コードをすべて削除する
一旦、改行コードをすべて削除します。
self.totaltxt = re.sub( r'\n', '', self.totaltxt )
問題ごとに改行する
問題ごとに改行するために、改行コードを入れます。
「肯定の先読み」という手法で、これがとてもわかりにくい。
self.totaltxt = re.sub( r'(問題\d.*?)(?=(問題\d))', r'\1\n', self.totaltxt)
以上のような処置でかなりいい感じのテキストが出来上がります。
問題1—-母体背景と胎児疾患の組合せで正しいのはどれか。 3 つ選べ。
問題2—-アレルギー性鼻炎の診断で原因抗原を特定するために行う検査はどれか。 2 つ選べ。
問題3—-胃全摘術後にみられる可能性があるのはどれか。 3 つ選べ。
……..
問題61—-40 歳の男性。 2 日前に発症した四肢の皮疹を主訴に来院した。瘙痒を伴う。両側下肢の写真(別冊No. 32)を別に示す。 原因として考えにくいのはどれか。
しかし、以下のようにこの方法ではダメな部分もあります。

このような部分はテキスト化するのは無理であり、これを画像として記録するしかないと思います。
テキストデータを mysql に書き込む
整理されたテキストデータが作成できれば、それをデータベース( mysql )に書き込むのは簡単です。
def txt2arr( self ):
al = self.totaltxt.split('\n')
for el in al:
ear = el.split('----')
self.alar.append(ear)
def insertData( self ):
conn = pymysql.connect( host='localhost',
db = self.mysqldb,
user = self.username,
password = self.password,
cursorclass=pymysql.cursors.DictCursor )
try:
with conn.cursor() as cursor:
sql = ( 'INSERT INTO 117a (qNo, quest) VALUES (%s, %s)')
cursor.executemany( sql, self.alar )
conn.commit()
finally:
conn.close()
手順は、
- 全体のテキストデータを改行コードで分割する
- それぞれの行を’—–‘で分割して、全体の2次元配列を作成
- それを一気にデータベースに書き込む。
もし、国家試験問題の pdf が同じフォーマットであれば、同じようにしてざっくりとはデータベース化できます。
細かい部分は後で修正するプログラムを組めばいいと思います。
