pdf ファイルから画像を抽出する
(2025-07-06)
pdf ファイルから画像を抽出することができます。
もちろん、文字 + 画像で何らかの文書(例えば word とか)を pdf としてエクスポートした場合に限ります。
例えば、 大腸腫瘍に対する内視鏡診断の進歩─早期大腸癌を中心に─ をローカルにダウンロードします。
python コード
python を使います。
まずは、モジュールをインポートします。
pip install fitzpip install PyMuPDFコードは、
import fitzimport os
filename = 'aaa.pdf'dir_name = os.path.splitext(filename)[0]img_dir = os.path.join(os.getcwd(), dir_name)
if not os.path.exists(img_dir): os.makedirs(img_dir)
doc = fitz.open(filename)
for page_index in range(len(doc)): page = doc[page_index] images = page.get_images(full=True)
for img_index, img in enumerate(images): xref = img[0] base_image = doc.extract_image(xref) image_bytes = base_image["image"] ext = base_image["ext"]
img_name = os.path.join(img_dir, f'image{page_index+1}_{img_index}.{ext}') with open(img_name, 'wb') as f: f.write(image_bytes) print(f"Saved: {img_name}")画像
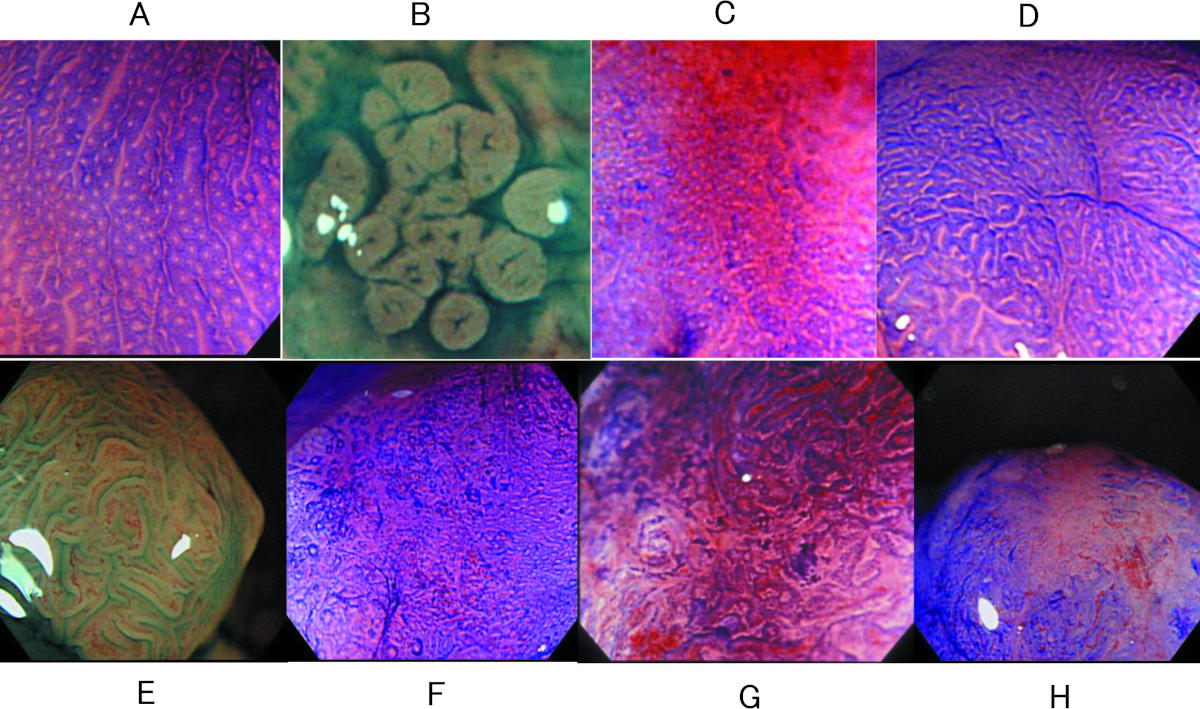
抽出された画像は 2.9 MB を超える大きなものなので解像度を横幅 1200 px に下げてみました。
それでもとてもきれいです。
著作権
本来は著作権があって、使用する場合には可能な限り出典を明記していますが、まとめて表示するような場合には出典をいちいち書くのもとても面倒なので省略させて頂いています。