python による英文解析
以前、英語の文章をスペースで区切って単語を取り出してデータベース化したことがあります。
どういう単語が多く使われているか、あるいは難易度はどのくらい必要なのかを確認するためだったのですが、英語は過去形・過去分詞・複数形などもあり、 データベースにそのまま記録するのでは分析になっていないと思っていました。
最近 AI が登場して、python であれば何でもできる感じがしていたので、今日 chatGPT に質問してみました。
最も簡単なサンプル
python の spacy というモジュールを使うと簡単に英文を解析できます。
まずは、spacy をインストール。
pip install spacy以下のような python を作成します。
import spacy
nlp = spacy.load("en_core_web_sm")doc = nlp("He ate two apples.")
for token in doc: print(token.text, "→", token.lemma_)実行すると、
He → heate → eattwo → twoapples → apple過去形や複数形を解析して元の単語を求めています。すごいですね。
Gutenberg プロジェクトから本をダウンロード・解析する
私の語彙力は 6,000 語くらいですが、簡単なものでもわからない単語はいっぱいあります。
この語彙力で読める本を chatGPT に訊いてみると「The Call of the Wild 」を勧めてくれました。 この本は若い時に日本語で読んだことがあります。
早速ダウンロードして解析してみました。
解析結果をデータベースに記録します。
import spacyimport mysql.connector
nlp = spacy.load("en_core_web_sm")
conn = mysql.connector.connect( host="localhost", user="root", password="pass", database="text_analysis")cursor = conn.cursor()
seen_lemmas = set()
with open("pg215.txt", "r", encoding="utf-8") as f: text = f.read()
doc = nlp(text)
sql = """ INSERT IGNORE INTO tokens (text, lemma, pos) VALUES (%s, %s, %s)"""
for token in doc: if ( token.is_alpha # アルファベットのみ and token.text.lower() == token.text # 小文字だけ(全大文字を除外) and len(token.text) > 1 # 1文字の単語は除外(必要なら) and token.lang_ == "en" # 英語で認識されたトークンのみ(言語モデル依存) ): lemma = token.lemma_ if lemma not in seen_lemmas: try: cursor.execute(sql, (token.text, lemma, token.pos_)) seen_lemmas.add(lemma) except mysql.connector.Error as e: print(f"MySQL Error: {e}")
conn.commit()cursor.close()conn.close()このプログラムでは、単語が unique に記録されます。
この本は、単語数が 31,797 あるのですが 1 分以内に解析・データベースへの記録が終了します。
記録された単語の難易度を確認するために、すでに作成してある単語リストの難易度を書き込んでみます。
まずは、CEFR の単語データベースと自分で作成した英検 2 級以上の単語データベースから難易度を書き込んで集計してみます。
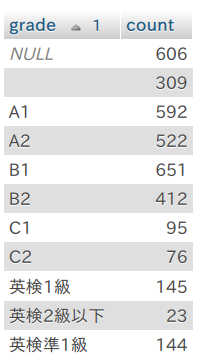
英検準 1 級以上が 290 語あります。
さらに、NULL や ブランクにはもっと難しい単語があります。
そこで、Gutenberg Readability Square というところで調べてみると、
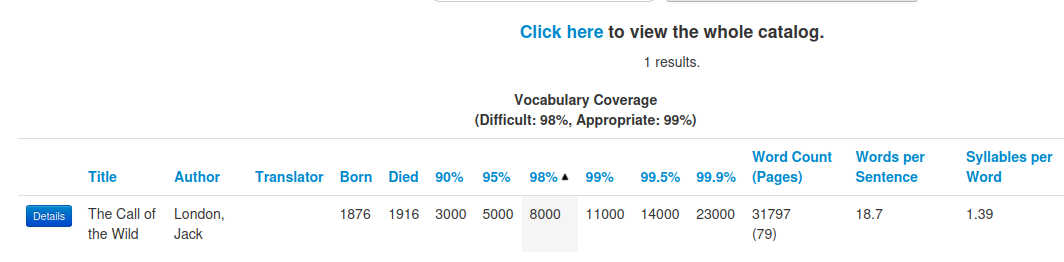
99.9 % 理解するためには語彙力 23,000 語必要なようです。私の英語レベルではどう考えても無理です。
もっと簡単な本を
Gutenberg Readability Square で調べて「The Yellow Wallpaper 」という作品をダウンロードしてみました。
データベースに記録して、CEFR データベースの grade を書き込んでみます。
UPDATE tokensJOIN STEP.wordlists ON tokens.lemma COLLATE utf8mb4_unicode_520_ci = wordlists.word COLLATE utf8mb4_unicode_520_ciSET tokens.grade = wordlists.grade;それぞれの grade でカウントします。
SELECT grade, COUNT(*) AS countFROM tokensGROUP BY gradeORDER BY grade;結果は、
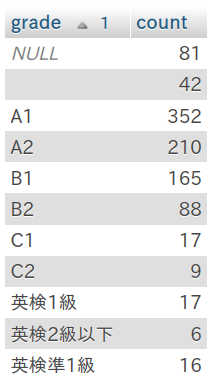
「The Call of the Wild 」よりもかなり簡単そうですね。
さらに、アルクの 12,000 語リストの難易度を書き込んでみます。
UPDATE tokensJOIN vocabura.wordlistON tokens.lemma = wordlist.wordSET tokens.grade = wordlist.levelWHERE tokens.grade IS NULL OR tokens.grade = '';grade が Null のものを検索すると、
この本はかなり簡単な部類に入るようですが、かなり難しい単語も含まれているようです。
この本の最初の内容を見てみましょう。
It is very seldom that mere ordinary people like John and myself secureancestral halls for the summer.
A colonial mansion, a hereditary estate, I would say a haunted house,and reach the height of romantic felicity—but that would be asking toomuch of fate!
Still I will proudly declare that there is something queer about it.
Else, why should it be let so cheaply? And why have stood so longuntenanted?単語は大体わかるのですが、スッと入ってきません。おそらく私には英語脳がないような気がしています。