日本語と英語の語彙
laravel で英語の単語テストのアプリを作成してみました。
まずは、単語のデータベースを作成する必要があります。
ネット上にはいろいろな単語リストがありますが、それなりに権威のあるものが必要だと思いました。
いろいろ調べて、CEFR(Common European Framework of Reference)というのがいいと思い Github からダウンロードしました。
それをデータベース化すると A1 から C2 までの 6 段階で合計 8,648 語になります。これをすべて記憶できれば、 グーテンベルクプロジェクトの多くの作品(特に18〜19世紀の英語小説など)を「辞書を頻繁に引かずに」読む準備はほぼ整っているようです。
ただ、これだけでは少し足りない気もしたので、「 英語漬け.com」というサイトにあるリストを頂いて、英検準2級以下・準1級・1級追加しました。
全部を合わせると 11,695 語になります。
私の脳細胞ではこのすべてを憶えるのは無理だと思いますが、ボケ防止の意味でも自作のアプリを作って、できるだけ多くの単語を記憶したいと思います。
最初のテスト
自分で作ったアプリでまずは 10,000 語のテストをやってみました。
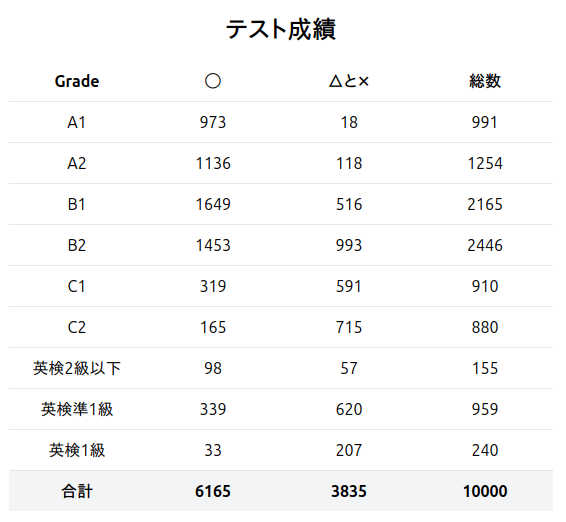
割と厳し目に判断して 6,165 語もあります。これは予想外に多いと感じました。でも英語の文章はスラスラ読めませんが。
おそらく医学用語に関してかなりカウントされているので、語彙としてかなり偏っているのだろうと思います。
日本語の語彙力
テストをしてみて英語の語彙力もさることながら、日本語の語彙力が足りないと感じました。概念的にぼんやりわかっていても、それを日本語にすることができません。
例えば「叙情的」という言葉は中学の頃から知っていましたが、深く追求することなく何となくぼんやりとわかったつもりでいました。
また、「革命的」と「革新的」の違いもよくわかっていませんでした。
日本語の勉強なんて高校卒業以来ほとんどやって来なかったので成長しなかったんだろうと思います。
日本語の語彙力をつけるためには、やはり本をよく読むということと疑問が湧いたら徹底的に調べることだと思います。でも今からでは遅いような気もします。
2 回目以降のテスト
2回目以降は、1回目で正解できなかったものだけを抽出して実行します。
少しやってみたところ、
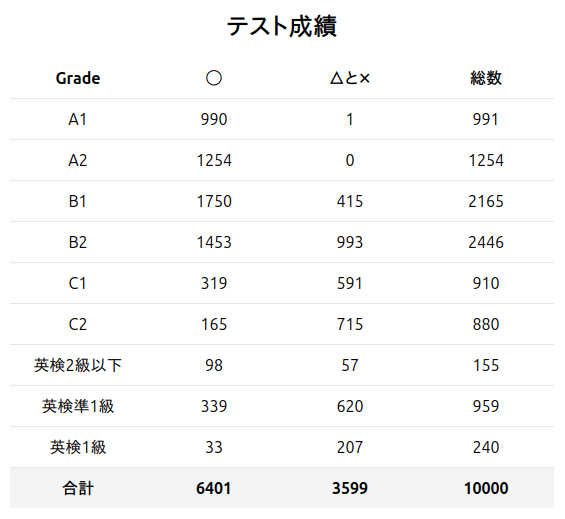
正解数がかなり増えてますが、プログラムに少し問題があってランダムに問題が出るようになっているので、続けて同じ問題が出ると正解にしてしまうことです。 こうして記憶したつもりでも、おそらく明日には忘れています。何らかの改善策を講ずる必要があります。
chatGPT と相談して、とりあえずは不正解の累積回数の少ない方から出題するようにしました。
// 不正解の単語だけ取得$this->words = Vocabulary::where('grade', $this->gradeName) ->whereIn('id', function ($query) { $query->select('latest_tests.vocabulary_id') ->from('word_tests as wt1') ->join(DB::raw('( SELECT vocabulary_id, MAX(id) as max_id FROM word_tests GROUP BY vocabulary_id ) as latest_tests'), 'wt1.id', '=', 'latest_tests.max_id') ->join('wordlists as wl', 'wt1.vocabulary_id', '=', 'wl.id') ->where('wl.grade', $this->gradeName) ->where('wt1.evaluation', '!=', '○'); }) ->withCount(['wordTests as test_count']) ->orderBy('test_count', 'asc') // テスト回数の少ない順 ->limit(20) ->get();ここまで複雑なクエリだと確認作業ができませんが、継続してみようと思います。
記憶法の工夫
しかし、単純に記憶しようとしても若い時と違って簡単には憶えられません。ただし、何らかの工夫をすれば憶えられるかもしれません。 それは語源であったり簡単な物語を利用することだと思います。
例えば「eavesdrop(盗聴する)」という難しい単語がありますが、「eaves」とは家の軒の意味です。軒から雨だれが落ちている時に、 雨宿りをした人が家の中の人の話を聞いてしまったという物語がイメージできて一発で記憶できました。
こういうことを利用すれば少し効率よく記憶できるかもしれません。