青空文庫 - 第3水準と第4水準の漢字を一括入力
青空文庫では古いドキュメントほど第3水準と第4水準の難しい漢字が入力されていないようです。
第3水準と第4水準の漢字は入力されていないため、
<img src="../../../gaiji/1-92/1-92-63.png" alt="※(「形のへん+おおざと」、第3水準1-92-63)" class="gaiji" />みたいにして、コード番号を書いて、時にはそれを画像化して貼り付けてあります。
しかしこのようにすると、特に iPad なんかで閲覧すると、
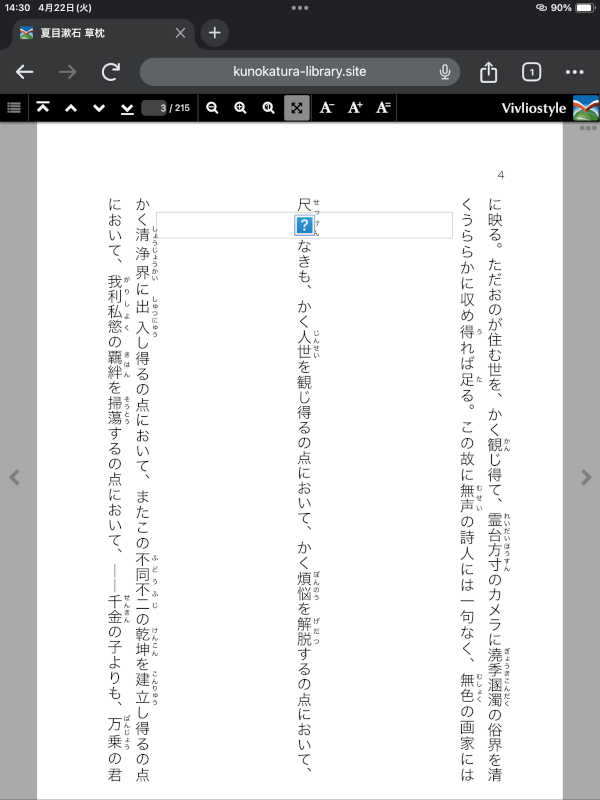
こんな風に乱れてしまいます。
そこで、第3水準と第4水準の漢字のコード・画像をちゃんとした漢字に置換しようと考えました。
第3水準と第4水準の漢字のリスト
ネット上で探してみたものの、csv でダウンロードできるようなものは発見できませんでした。
https://www.asahi-net.or.jp/~ax2s-kmtn/ref/jisx0213/index.html?utm_source=chatgpt.com に第3水準と第4水準の漢字がすべて提示されているようなので、これをデータベース化します。こういうことをやらせると chatGPT はとても有能です。最初はおかしなコードを書きましたが、一つ一つ誘導してやればかなりのスピードでコードを書いてくれます。
上のページをローカルにダウンロードして以下のような php を作成しました。
<?php$html = file_get_contents('all.html');libxml_use_internal_errors(true);$doc = new DOMDocument();$doc->loadHTML($html);$xpath = new DOMXPath($doc);
$tables = $xpath->query('//table[@class="basic"]');$result = [];foreach ($tables as $table) { $summary = $table->getAttribute('summary');
if (preg_match('/JIS X 0213 (\d)面(\d+)区/', $summary, $matches)) { $men = $matches[1]; $ku = $matches[2]; $jis_base = "$men-$ku";
$rows = $table->getElementsByTagName('tr'); $colIndex = 1; foreach ($rows as $tr) { $tds = $tr->getElementsByTagName('td'); foreach ($tds as $td) { $char = trim($td->nodeValue); if ($char !== '') { $result[] = [ 'jisCode' => "$men-$ku-$colIndex", 'kanji' => $char ]; $colIndex++; } } } }}
foreach ($result as $item) { echo $item['jisCode'] . " : " . $item['kanji'] . "<br>";}
try { $pdo = new PDO("mysql:host=localhost;dbname=aozora;charset=utf8mb4", 'root', 'pass'); $pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); $pdo->beginTransaction(); $stmt = $pdo->prepare("INSERT INTO `JIS X 0213` (code, kanji) VALUES (:code, :kanji)");
foreach ($result as $item) { $stmt->execute([ ':code' => $item['jisCode'], ':kanji' => $item['kanji'] ]); }
$pdo->commit(); echo "<br><strong>データベースへの保存が完了しました!</strong>";} catch (PDOException $e) { if ($pdo->inTransaction()) { $pdo->rollBack(); } echo "エラー: " . $e->getMessage();}このデータベースを csv 出力したものを ここ に置いておきます。
すべての html をデータベース化する
私のライブラリに収録されているすべての作品をデータベース化します。全部で 3,215 作品あります。
中には 900 ページを超えるような大作もあります。
html タグの <body></body>の部分を抽出してデータベースに記録します。
<?php$baseDir = '../aozora/shelf/';$pdo = new PDO('mysql:host=localhost;dbname=aozora;charset=utf8mb4', 'root', 'pass');
$authors = array_filter(scandir($baseDir), function($author) use ($baseDir) { return is_dir($baseDir . $author) && $author !== '.' && $author !== '..';});
foreach ($authors as $author) { $authorDir = $baseDir . $author . '/'; $files = array_filter(scandir($authorDir), function($file) use ($authorDir) { return is_file($authorDir . $file) && pathinfo($file, PATHINFO_EXTENSION) === 'html'; });
foreach ($files as $file) { $filePath = $authorDir . $file; $html = file_get_contents($filePath); $title = pathinfo($file, PATHINFO_FILENAME); preg_match('/<body[^>]*>(.*?)<\/body>/us', $html, $bodyMatch); $body = $bodyMatch[1] ?? '';
$stmt = $pdo->prepare("INSERT INTO works (author, title, content) VALUES (?, ?, ?)"); $stmt->execute([$author, $title, $body]);
echo "登録完了: $author - $title\n"; }}?>正規表現によってタグを抽出する
データベース化された本のコードから以下のような部分を正規表現によって抽出します。
<img src="../../../gaiji/2-92/2-92-67.png" alt="※(「飮のへん+氣」、第4水準2-92-67)" class="gaiji" />つまり、<img ... class="gaiji" /> で挟まれた文字列を抜き出します。
<?php
ini_set('memory_limit', '512M');$pdo = new PDO('mysql:host=localhost;dbname=aozora;charset=utf8', 'root', 'pass');
$already = [];
$stmt = $pdo->query("SELECT id, content FROM works");$works = $stmt->fetchAll(PDO::FETCH_ASSOC);
foreach ($works as $work) { $content = $work['content'];
preg_match_all('/<img[^>]*class="gaiji"[^>]*>/i', $content, $matches);
foreach ($matches[0] as $tag) { if (!isset($already[$tag])) { $insert = $pdo->prepare("INSERT INTO gaiji (tag, kanji, note) VALUES (?, '', '')"); $insert->execute([$tag]); $already[$tag] = true; } }}
echo "works.contentからgaijiを抽出して保存しました。\n";抽出したタグから漢字コードを抽出する
今度はタグから漢字コードを抽出します。
つまり、
<img src="../../../gaiji/2-92/2-92-67.png" alt="※(「飮のへん+氣」、第4水準2-92-67)" class="gaiji" />から
2-92-67という文字列を抽出してデータベースに記録します。
<?phptry { $pdo = new PDO("mysql:host=localhost;dbname=aozora;charset=utf8mb4", 'root', 'pass'); $pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $pdo->query("SELECT id, tag FROM gaiji WHERE tag IS NOT NULL"); $rows = $stmt->fetchAll(PDO::FETCH_ASSOC); $updateStmt = $pdo->prepare("UPDATE gaiji SET code = :code WHERE id = :id");
foreach ($rows as $row) { $id = $row['id']; $tag = $row['tag'];
// 正規表現でJISコード(1-13-21など)を抽出 if (preg_match('/(\d{1,2}-\d{1,2}-\d{1,2})/', $tag, $matches)) { $code = $matches[1];
$updateStmt->execute([ ':code' => $code, ':id' => $id ]); } } echo "code カラムの更新が完了しました!";} catch (PDOException $e) { echo "エラー: " . $e->getMessage();}外字コードを漢字に置換する
コンテンツの中にある外字コードを漢字に置換します。
つまり、
<img src="../../../gaiji/2-92/2-92-67.png" alt="※(「飮のへん+氣」、第4水準2-92-67)" class="gaiji" />を
餼という漢字に置き換えます。
<?php$pdo = new PDO("mysql:host=localhost;dbname=aozora;charset=utf8mb4", 'root', 'pass');$pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$sql = "SELECT tag, kanji FROM gaiji WHERE tag IS NOT NULL AND kanji IS NOT NULL";$gaijiList = $pdo->query($sql)->fetchAll(PDO::FETCH_ASSOC);
$selectStmt = $pdo->prepare("SELECT id, content FROM works WHERE content LIKE :tag");$updateStmt = $pdo->prepare("UPDATE works SET content = :newContent WHERE id = :id");
foreach ($gaijiList as $gaiji) { $tag = $gaiji['tag']; $kanji = $gaiji['kanji'];
$escapedTag = addcslashes($tag, '%_'); $likeTag = "%$escapedTag%";
$selectStmt->execute([':tag' => $likeTag]); $works = $selectStmt->fetchAll(PDO::FETCH_ASSOC);
foreach ($works as $work) { $updatedContent = str_replace($tag, $kanji, $work['content']);
if ($updatedContent !== $work['content']) { $updateStmt->execute([ ':newContent' => $updatedContent, ':id' => $work['id'] ]);
echo "置換: works.id = {$work['id']} に {$kanji} を挿入<br>"; } }}?>これは凄まじい数の比較をおこなっているのでかなり時間がかかります。私のコンピュータで 10 分くらいでした。
html 文書作成
上で編集されたデータを元に新しい html 文書を作成します
<?php
ini_set('memory_limit', '512M');$pdo = new PDO('mysql:host=localhost;dbname=aozora;charset=utf8mb4', 'root', 'pass');$outputDir = 'output';$gaiji = [];$sql = "SELECT tag, kanji FROM gaiji WHERE tag IS NOT NULL AND kanji IS NOT NULL";$stmt = $pdo->query($sql);while ($row = $stmt->fetch(PDO::FETCH_ASSOC)) { $gaiji[$row['tag']] = $row['kanji'];}
$sql = "SELECT id, author, title, content FROM works";$stmt = $pdo->query($sql);$works = $stmt->fetchAll(PDO::FETCH_ASSOC);
function sanitizeFileName($string) { $string = mb_convert_kana($string, 'as'); // 全角→半角 $string = preg_replace('/[\/:*?"<>|]/u', '_', $string); return trim($string);}
foreach ($works as $work) { $content = $work['content']; $original = $content;
foreach ($gaiji as $tag => $kanji) { if (strpos($content, $tag) !== false) { $content = str_replace($tag, $kanji, $content); } } $html = <<<HTML<!DOCTYPE html><html lang="ja"><head> <meta http-equiv="content-type" content="text/html; charset=UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="content-style-type" content="text/css" /> <link rel="stylesheet" type="text/css" href="../../viewer/css/style.css" /> <title>{$work['author']} {$work['title']}</title> <script type="text/javascript" src="../../jquery-1.4.2.min.js"></script> <link rel="Schema.DC" href="http://purl.org/dc/elements/1.1/" /> <meta name="DC.Title" content="{$work['title']}" /> <meta name="DC.Creator" content="{$work['author']}" /> <meta name="DC.Publisher" content="青空文庫" /></head><body>{$content}</body></html>HTML;
$authorDir = $outputDir . '/' . sanitizeFileName($work['author']); if (!is_dir($authorDir)) { mkdir($authorDir, 0777, true); } $filePath = $authorDir . '/' . sanitizeFileName($work['title']) . '.html'; file_put_contents($filePath, $html); echo "書き出し: {$filePath}\n";}?>ローカルで確認
テザリング環境で linux mint 22 の localhost に iPad からアクセスして確認します。
sudo ufw allow 8000/tcp起動するための start-webserver を書き換えます。
if command -v php >&/dev/null; then open_url php -S 0.0.0.0:$PORTelse echo "PHP is not installed. Please install PHP and rerun this script." exit 1fiそうすると、iPad から linux mint 22 の localhost にアクセスできます。

「尺縑」という字がきれいに表示されるようになりました。